Making S3 (almost) as fast as local memory
AWS Lambda is amazing, and as I talked about last time, can be used for some pretty serious compute. But many of our potential use cases involve data preprocessing and data manipulation -- the so-called extract, transform, and load (ETL) part of data science. Often people code up Hadoop or Spark jobs to do this. I think for many scientists, #thecloudistoodamnhard -- learning to write Hadoop and Spark jobs requires both thinking about cluster allocation as well as learning a Java/Scala stack that many are unfamiliar with. What if I just want to resize some images or extract some simple features ? Can we use AWS Lambda for high-throughput ETL workloads? I wanted to see how fast PyWren could get the job done. This necessitated benchmarking S3 read and write from within Lambda.
I wrote an example
script,
s3_benchmark.py to
first write a bunch of objects with pseudorandom data to s3, and then
read those objects out. The data is pseudorandom to make sure our
results aren't confounded by compression, and everything is
done with streaming file-like objects in Python. To write 1800 2GB objects
to the S3 bucket jonas-pywren-benchmark I can use the following
command:
$ python s3_benchmark.py write --bucket_name=jonas-pywren-benchmark \ --mb_per_file=2000 --number=1800 --key_file=big_keys.txt
Each object is placed at a random key, and the keys used are written
to big_keys.txt, one per line. This additionally generates a python pickle
of (start time, stop time, transfer rate) for each job. We can then
read these generated s3 objects with with :
$ python s3_benchmark.py read --bucket_name=jonas-pywren-benchmark \ --number=1800 --key_file=big_keys.txt
We can look at the distribution of per-job throughput, the job runtimes for the read and write benchmarks, and the total aggregate throughput (colors are consistent -- green is write, blue is read):
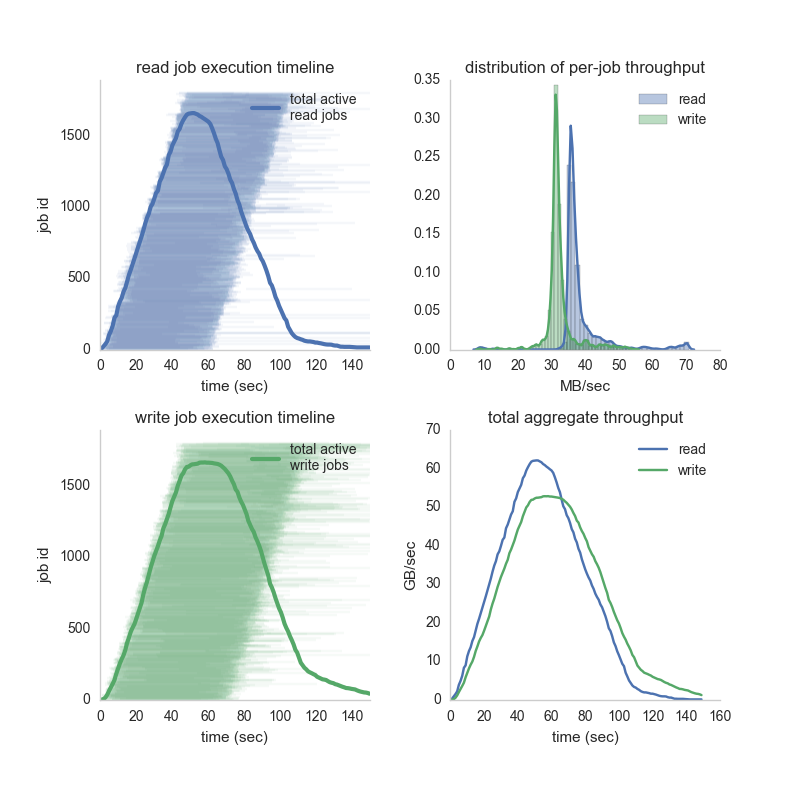
Note that at the peak, we have over 6O GB/sec read and 50 GB/sec write to S3 -- that's nearly half a terabit a second of IO! For comparison, high-end Intel Haswell Xeons get about ~100GB/sec to RAM. On average, we see per-object write speeds of ~30 MB/sec and read speeds are ~40MB/sec. The amazing part is this is nearly linear scaling of read and write throughput to S3.
I struggle to comprehend this level of scaling. We're working on some applications now where this really changes our ability to quickly and easily try out new machine learning and data analysis pipelines. As I mentioned when talking about compute throughput, this is peak performance -- it's likely real workloads will be a bit slower. Still, these rates are amazing!